OpenAI 사용량 대시보드 가이드
이 문서는 GPT Prompt Tester의 사용량 대시보드에서 제공하는 비용 · 토큰 · 호출 수 · 모델별/툴별 비중 · latency를 “어떻게 읽고, 무엇을 개선할지”까지 연결해서 안내합니다.
최종 업데이트: 2026. 01. 29
대시보드 개요 · 무엇을 볼 수 있나요?
OpenAI 사용량 대시보드는 “내가 언제, 어떤 모델로, 얼마를 쓰고 있는지”를
한 화면에서 파악할 수 있도록 설계되었습니다.
GPT Prompt Tester는 각 호출의 비용·토큰·모델·툴·latency를 자동 기록하고,
선택한 기간 기준으로 이를 순서대로 분석해 보여줍니다.
-
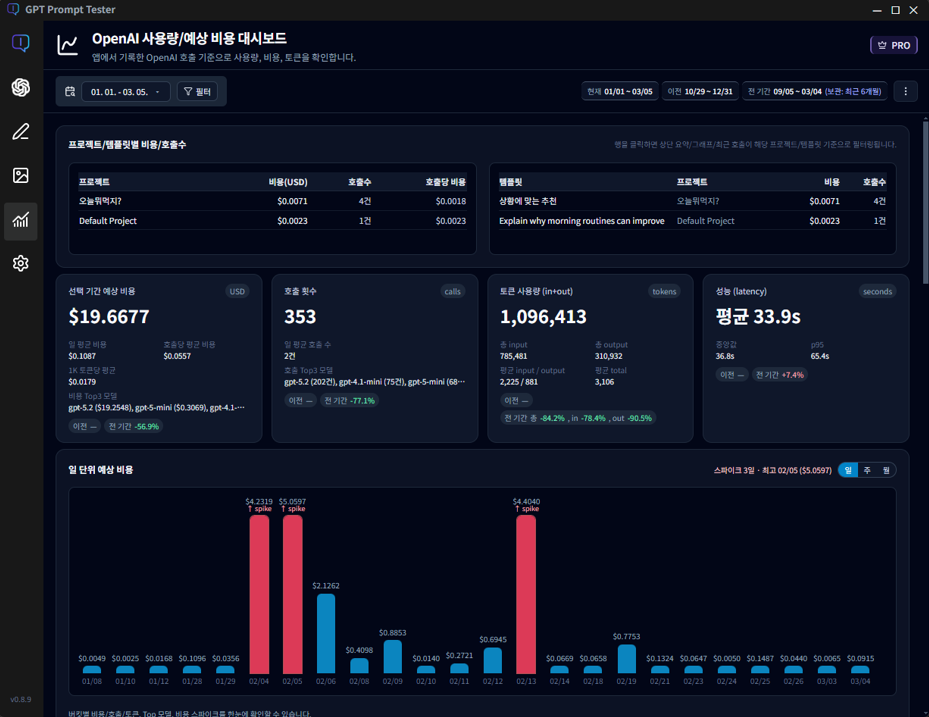
① 요약 카드
선택한 기간 동안의 총 예상 비용, 호출 수, 토큰 사용량, 평균 latency를 가장 먼저 확인할 수 있습니다. 더보기… -
② 일 단위 예상 비용
날짜별 비용 사용량을 막대 그래프로 보여주며, 특정 날짜의 비용 스파이크를 즉시 파악할 수 있습니다. 더보기… -
③ 모델별 비용 · 툴 사용 비중
어떤 모델이 비용을 많이 차지하는지, web_search 같은 툴이 비용에 얼마나 영향을 주는지를 한눈에 비교합니다. 더보기… -
④ 누적 비용 트렌드
기간 동안 비용이 어떻게 누적되었는지와 함께, 이전 기간 대비 증가 속도(pace)를 비교해 볼 수 있습니다. 더보기… -
⑤ 모델별 latency 추이
모델별 평균 응답 시간이 날짜 흐름에 따라 어떻게 변하는지 보여주며, 일반 호출과 web_search 호출의 지연 시간 차이도 구분해 확인할 수 있습니다. 더보기… -
⑥ 시간대 · 요일별 호출 패턴
언제 호출이 가장 많이 발생하는지, 사용 습관과 트래픽 집중 시간대를 분석할 수 있습니다. 더보기… -
⑦ 호출 리스트 (원천 데이터)
대시보드에 표시된 모든 수치의 기반이 되는 개별 호출 로그를 그대로 확인할 수 있습니다. 더보기…
💡팁: 대시보드의 목적은 “절약”만이 아니라, “효율”입니다. 같은 품질을 더 빠르고 싸게 만드는 힌트를 얻는 데 가장 유용합니다.
🔅참고: 프로젝트·템플릿별 비용/호출 분석은 PRO 라이선스에서 제공되는 기능입니다.
PRO에서는 호출 데이터를 프로젝트·템플릿 단위로 분리해,
어떤 작업/실험이 실제로 비용을 소모하고 있는지까지 추적할 수 있습니다.
기간 선택(필터) · 대시보드 해석의 출발점
OpenAI 사용량 대시보드는 선택한 기간을 기준으로
비용·토큰·호출 수·latency·그래프를 모두 계산합니다.
따라서 기간 선택 방식에 따라 같은 데이터라도 전혀 다른 해석이 나올 수 있습니다.
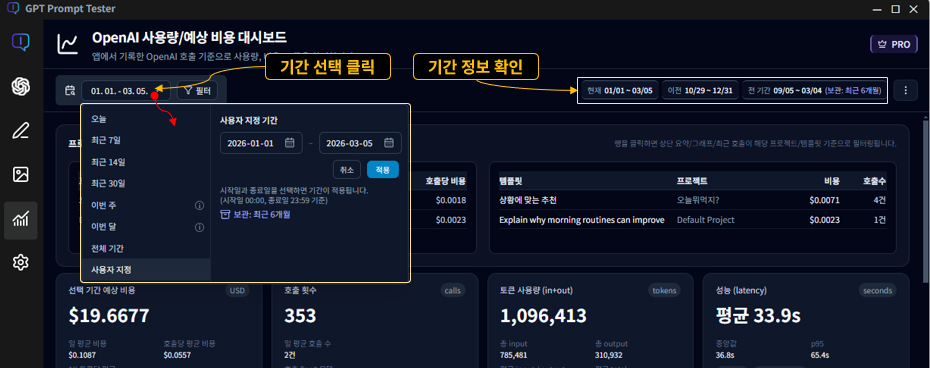
2-1. 기간 선택 메뉴 구성
좌측 상단의 기간 선택 버튼을 클릭하면, 자주 사용하는 기간 프리셋과 사용자 지정 기간을 선택할 수 있습니다.
- 오늘 : 오늘(00:00~현재) 발생한 호출만 포함
- 최근 7일 : 오늘을 포함한 최근 7일
- 최근 14일 / 30일 : 오늘 포함 N일 기준
- Week to date / Month to date : 주/월 시작일부터 오늘까지
- 전체 기간 : 저장된 모든 사용 기록
- 사용자 지정 : 시작일·종료일을 직접 선택
2-2. ‘최근 7일’의 정확한 의미
“최근 7일”은 오늘을 포함한 7일을 의미합니다.
예를 들어 12월 15일에 최근 7일을 선택하면,
12/09 ~ 12/15까지의 데이터가 집계됩니다.
2-3. 이전 기간(비교 기간) 표시
대시보드 상단에는 현재 기간과 함께 이전 기간이 자동으로 표시됩니다.
이전 기간은 현재 선택한 기간과 동일한 길이를 갖는 바로 앞 구간입니다.
- 현재 기간: 11/16 ~ 12/15
- 이전 기간: 10/17 ~ 11/15
이 두 기간을 비교해 비용·호출 수·토큰 사용량의 증감률(전기간 대비)이 계산됩니다.
💡팁: 하루짜리 기간(오늘)은 누적 트렌드나 비교 그래프의 의미가 적기 때문에, 앱 설정에 따라 일부 그래프 섹션이 자동으로 숨겨질 수 있습니다.
상단 필터 · “무엇을 기준으로 보고 있나”
대시보드 상단 필터는 이 화면의 모든 지표(비용·토큰·지연·그래프)의 기준을 결정합니다.
이제는 기간뿐 아니라 호출 유형(기능) / 글작성 단계 / 모델 / 툴까지 함께 제한되므로,
분석 전 “현재 어떤 필터가 켜져 있는지”부터 확인하는 것이 중요합니다.

3-1. 기간 필터(좌측)
- 최근 7일 / 14일 / 30일 같은 프리셋과 사용자 지정 기간을 선택할 수 있습니다.
- 선택한 기간을 기준으로 모든 비용·토큰·그래프·표가 다시 계산됩니다.
- 기간 변경 시, 이전 기간(비교)도 함께 계산되어 증감 비교가 가능합니다.
3-2. 기능 필터(호출 유형)
기능 필터는 “이 비용이 어떤 화면/기능에서 발생했는지”를 가장 빠르게 나누는 기준입니다. 글작성 기능이 추가되면서, 이제 대시보드가 Playground 호출뿐 아니라 글작성 과정에서 발생한 호출까지 함께 기록합니다.
- 전체 : 모든 호출(플레이그라운드 + 글작성 + 기타)을 합산
- 플레이그라운드 : Prompt Playground 실행에서 발생한 호출만
- 글작성 : Writing Studio(글작성 기능)에서 발생한 호출만
- 이미지 : Image Maker 기능에서 발생한 호출만
- 기타 : 앱 내 기타 기능(예: 특정 유틸/도우미 호출 등)에서 발생한 호출만
3-3. 글작성 단계 필터(글작성 선택 시)
기능에서 글작성을 선택하면, 상단에 글작성 단계 필터가 함께 나타납니다.
글작성은 보통 여러 번의 API 호출로 구성되기 때문에,
“어느 단계가 비용/지연을 밀어 올리는지”를 단계별로 분리해서 볼 수 있습니다.
- 전체 : 글작성 관련 모든 단계 호출을 합산
- 제목 추천 : 제목 생성(추천) 단계 호출만
- 초안 작성 : 본문 초안 생성 단계 호출만
3-4. 모델 필터
- 전체 또는 특정 모델(gpt-4, gpt-4o, gpt-5 등)만 선택할 수 있습니다.
- 특정 모델을 선택하면 해당 모델 호출만 대상으로 비용/latency/토큰 분석이 이루어집니다.
- 글작성 기능은 단계별로 서로 다른 모델을 쓸 수도 있으므로, 모델 필터로 원인 모델을 좁히기 좋습니다.
3-5. 툴 필터
- 전체 / web_search / image_gen / 없음 등 툴 사용 여부로 필터링할 수 있습니다.
- web_search만 선택하면, “검색 때문에 비용/지연이 늘었는지”를 즉시 분리해 볼 수 있습니다.
- image_gen은 대부분 Image Maker에서 사용되는 툴로 볼 수 있습니다.
- 툴 필터는 비용 급증 원인을 가장 빠르게 좁히는 데 효과적입니다.
3-6. 필터 조합 활용 예
- 글작성 + 초안 작성 + 특정 모델 : 초안 단계에서 특정 모델이 비용을 올리는지 확인
- 플레이그라운드 + web_search : 검색 사용이 비용/지연에 미친 영향만 분리
- 전체 + 특정 모델 : 장기적으로 비효율적인 모델인지(전체 사용 기준) 판단
- 글작성 + 제목 추천 : 제목 추천 단계가 과도하게 호출되고 있는지 점검
💡팁: “데이터가 이상하다”고 느껴질 때,
가장 먼저 확인해야 할 것은 기능(호출 유형) 필터입니다.
글작성/이미지 호출이 합산되면, 기존보다 총 호출/비용이 커 보일 수 있습니다.
목적에 맞게 기능·단계 필터로 먼저 분리한 뒤 해석하세요.
요약 카드(Overview) 읽는 법
화면 상단의 요약 카드는 “지금 선택한 기간의 핵심 결과”를 4~5개의 숫자로 압축해서 보여줍니다.
먼저 여기서 비용/호출/토큰/latency의 이상 징후를 감지한 뒤,
아래 그래프(일별 비용, 모델별 분석, 툴 비중, latency trend)로 내려가 원인을 찾는 흐름이 가장 빠릅니다.

4-1. 요약 카드 4개가 의미하는 것
- 선택 기간 예상 비용 (USD) : 현재 선택한 기간에 발생한 총 비용입니다. 아래에 일 평균 비용, 호출당 평균 비용, 1K 토큰당 평균 비용 같은 “효율 지표”가 함께 표시됩니다.
- 호출 횟수 (calls) : 선택 기간 동안 실행한 횟수입니다. 일 평균 호출 수와 함께, 많이 쓴 모델(Top 3 모델)도 같이 보여줍니다.
- 토큰 사용량 (tokens, in+out) : 입력(input)과 출력(output) 토큰 총합입니다. 아래에는 총 input / 총 output, 평균 input/output 같은 “출력 과다/과소” 힌트가 표시됩니다.
- 성능 (latency, seconds) : 평균 응답 시간(초)입니다. 함께 표시되는 중앙값, p95는 “가끔 매우 느린 호출이 있는지(꼬리)”를 판단하는 데 유용합니다.
4-2. ‘증감률(Δ)’ 배지(이전 기간/전 기간) 보는 순서
각 카드 하단의 배지는 현재 기간을 기준으로 이전 기간 또는 전 기간과 비교한 변화율(%)입니다. 보통은 아래 순서로 보면 원인 추적이 빨라집니다.
- 1) 비용(USD)이 늘었는지/줄었는지 먼저 확인
- 2) 호출 수(calls) 변화가 같이 있었는지 확인
- 3) 호출 수 변화가 크지 않은데 비용만 변했다면 : 출력이 길어졌거나(max output tokens), web_search 같은 툴 사용, 혹은 모델 변경이 원인일 가능성이 큽니다.
- 4) latency가 상승했다면 : 툴 사용(web_search), 출력 증가, 특정 모델의 지연 증가(모델별 trend)를 의심하고 아래 섹션에서 확인합니다.
💡팁: “비용↑ + 호출↑”은 사용량 자체가 늘어난 경우가 많고, “비용↑ + 호출↔”은 한 번 실행당 더 비싼 조건(툴/출력/모델)으로 바뀐 경우가 많습니다.
일별 트렌드 · 비용/호출 수/토큰
일별 트렌드 그래프는 “어느 날 무엇이 달라졌는지”를 가장 빠르게 보여줍니다.
특히 특정 날짜에 비용이 급증(spike)했을 때,
그 날의 호출 내역으로 바로 내려가 원인을 추적하기에 최적화된 화면입니다.
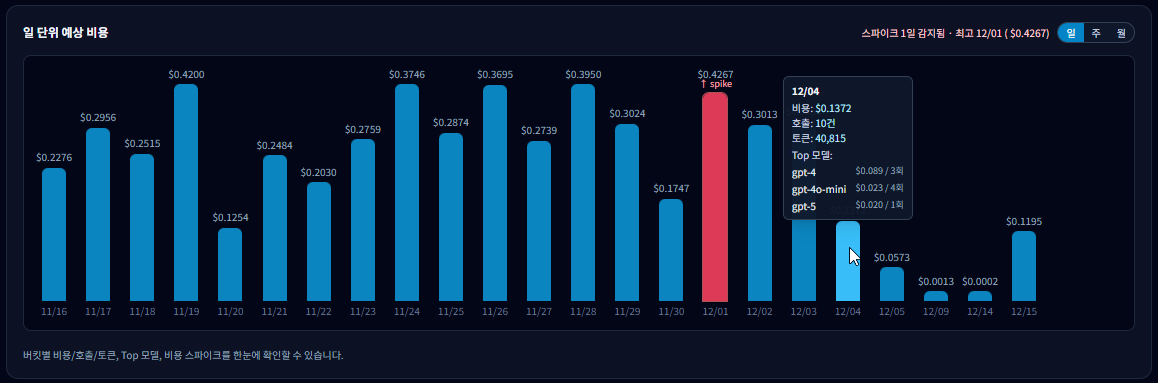
5-1. 이 그래프에서 가장 먼저 볼 것
- 어느 날짜에 막대가 튀었는지(스파이크)
- 그 날의 비용이 평소 대비 얼마나 컸는지
- 연속적인 증가인지, 하루만 튄 단발성 이벤트인지
5-2. 보기 단위 전환(일 · 주 · 월)
이 그래프는 기본적으로 일 단위로 표시되지만, 우측 상단의 버튼을 통해 주 단위 / 월 단위로도 전환할 수 있습니다.
- 일 단위 : 특정 날짜의 비용 스파이크를 정확히 찾을 때 가장 유용
- 주 단위 : 요일 편차를 제거하고, “이번 주 vs 지난 주” 같은 흐름을 볼 때 적합
- 월 단위 : 실험 규모가 커졌을 때, 전체 비용 추세와 증가 속도를 한눈에 파악
5-3. 툴팁(hover)으로 확인할 수 있는 정보
막대 위에 마우스를 올리면, 해당 날짜의 상세 정보가 툴팁으로 표시됩니다.
- 해당 날짜의 총 비용
- 호출 수 (실행 횟수)
- 총 토큰 사용량
- Top 모델 (그 날 비용에 가장 많이 기여한 모델)
5-4. 스파이크 원인 분석 순서
- 호출 수가 급증했다면 : 실험 횟수 자체가 늘어난 날일 가능성이 큽니다.
- 호출 수는 비슷한데 비용만 늘었다면 : web_search 같은 툴 사용, 출력 길이 증가, 또는 모델 변경을 의심해야 합니다.
- 특정 모델 하나가 대부분을 차지한다면 : 모델별 비용/latency 섹션에서 해당 모델을 집중 확인합니다.
💡팁: 스파이크가 발생한 날짜를 기억한 뒤, 아래의 호출 리스트에서 해당 날짜로 내려가면 “어떤 프롬프트·어떤 모델·어떤 툴”이 비용을 만들었는지 바로 확인할 수 있습니다.
모델·툴별 사용량/비용 분석
같은 기간이라도 어떤 모델을 주로 썼는지에 따라 비용·속도·출력 길이 성향이 크게 달라질 수 있습니다.
이 섹션은 “어떤 모델이 비용을 먹고 있는지”와 “왜 비싸졌는지(출력/툴/latency)”를 빠르게 찾는 데 가장 직접적입니다.
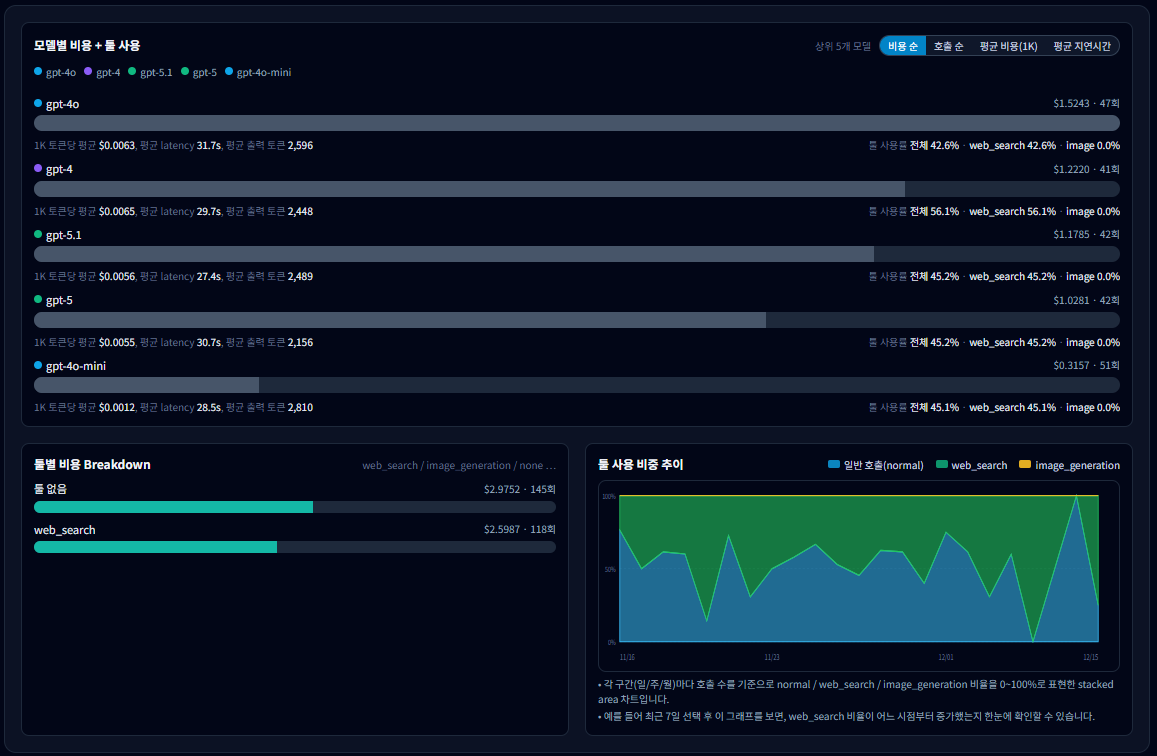
6-1. 모델별 리스트에서 무엇을 보나요?
- 모델별 총 비용 : 기간 내 비용이 큰 모델부터 확인합니다. (가장 먼저 “비용 Top 모델” 찾기)
- 호출 수(Calls) : 비싼 이유가 “많이 호출해서”인지, “한 번이 비싸서”인지 구분합니다.
- 1K 토큰당 평균 비용 : 같은 토큰을 써도 모델마다 단가/효율이 달라, 장기적으로 비용 차이를 만듭니다.
- 평균 latency : 느려짐의 원인이 특정 모델인지 확인합니다. (특히 web_search 사용 여부와 함께 보면 좋음)
- 평균 출력 토큰 : 특정 모델에서 답이 유난히 길어지는 패턴(=비용 증가 원인)을 찾습니다.
- 툴 사용률 : 모델별로 web_search / image_generation 같은 툴 비중이 같이 표시되면, “모델 때문인지(단가)” vs “툴 때문인지(추가 비용/지연)”를 빠르게 나눌 수 있습니다.
6-2. 정렬(Sort)을 바꿔가며 보는 이유
모델별 리스트는 상단의 정렬 기준을 바꿔가며 보는 것이 핵심입니다.
같은 데이터라도 어떤 기준으로 정렬하느냐에 따라
“비용 원인”이 전혀 다르게 보일 수 있습니다.
- 비용순 정렬 : 현재 기간에 총 비용을 가장 많이 차지한 모델을 빠르게 찾을 때
- 호출 수순 정렬 : 비싼 이유가 “많이 불려서”인지 확인할 때
- 1K 토큰당 평균 비용순 : 장기적으로 비효율적인(단가가 높은) 모델을 찾을 때
- 평균 latency순 : 응답 지연의 주범이 되는 모델을 찾을 때
💡팁: 비용순 → 호출 수순 → 1K 토큰당 비용순으로 정렬을 바꿔가며 보면, “많이 써서 비싼지 / 한 번이 비싼지 / 구조적으로 비효율적인지”를 빠르게 구분할 수 있습니다.
6-3. 툴별 비용 Breakdown(하단 좌측) 읽는 법
- 이 차트는 선택 기간의 비용을 normal / web_search / image_generation 등 “툴 단위”로 나눠 보여줍니다.
- 비용이 늘었는데 호출 수는 비슷하다면, 여기서 web_search 비중 증가 같은 원인을 발견하는 경우가 많습니다.
- 툴이 “none(일반 호출)”에 몰려 있으면, 원인은 대체로 모델 선택 또는 출력 길이 쪽일 가능성이 큽니다.
6-4. 툴 사용 비중 추이(하단 우측)로 “언제부터 달라졌나” 찾기
- 구간(일/주/월 버킷)마다 호출을 기준으로 normal / web_search / image_generation 비율이 어떻게 변했는지 보여줍니다.
- 특정 시점부터 web_search 영역이 커졌다면, 그 시점의 일별 트렌드/호출 리스트로 내려가 원인을 추적하면 빠릅니다.
6-5. “비용 줄이기”에 바로 쓰는 대표 패턴
- 출력이 길어져서 비싸다면: 프롬프트에 분량 제한(예: 10줄/요약/표 형식)을 명시하거나 max output tokens를 조정합니다.
- 기본 작업은 가벼운 모델로, 중요한 작업만 고성능 모델로: 모델을 역할별로 분리하면 비용이 안정됩니다.
- web_search/추론 옵션을 상시로 켜두지 말고: “필요한 호출에서만” 켜는 방식이 가장 효과적입니다.
💡팁: 이 섹션은 “원인 후보”를 빠르게 좁히는 곳입니다. 비용이 튀는 모델/툴/시점을 찾았으면, 다음은 일별 트렌드(스파이크)와 호출 리스트에서 실제 사례를 확인하면 됩니다.
누적 비용 트렌드(Cumulative) 해석
누적 비용 그래프는 선택한 기간 동안의 비용을 시간 순서대로 계속 더해
보여주는 차트입니다.
선의 기울기가 가파를수록 해당 시점의 비용 증가 속도가 빠르다는 뜻이며,
“이 속도라면 기간이 끝날 때 얼마가 될지”를 직관적으로 파악할 수 있습니다.
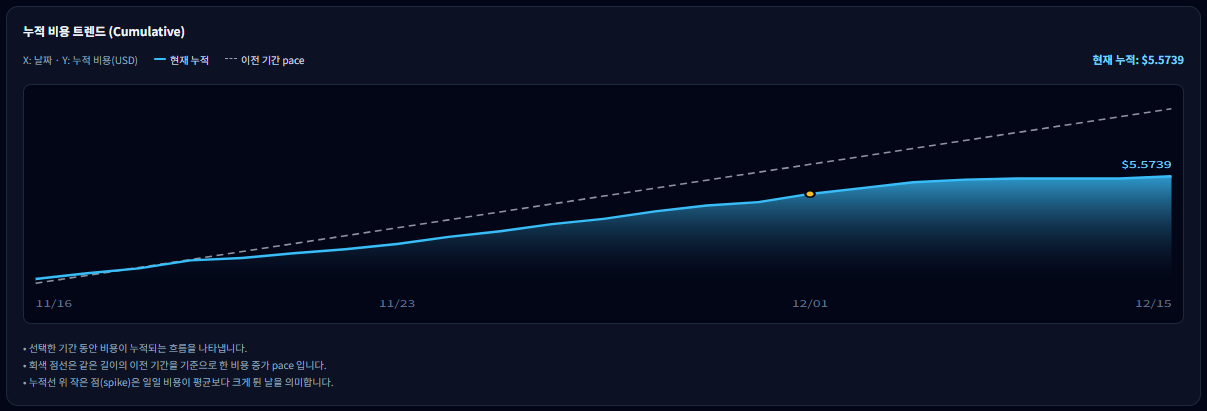
7-1. 현재 누적선과 이전 기간 pace(점선)
- 실선(현재 누적) : 선택한 기간 동안 실제로 누적된 비용입니다.
- 점선(이전 기간 pace) : 이전 기간과 같은 속도로 비용을 쓴다고 가정했을 때의 기준선입니다.
- 현재 누적선이 점선 위에 있으면: 이전 기간보다 더 빠른 속도로 비용을 사용 중
- 점선 아래에 있으면: 이전 기간보다 비교적 안정적으로 사용 중
7-2. 이 그래프를 언제 봐야 하나요?
- 월 단위·주 단위로 예산 소진 속도를 감시할 때
- 중간에 큰 스파이크가 전체 예산에 어떤 영향을 주는지 볼 때
- “이번 기간 끝나기 전에 초과할 것 같은지”를 미리 판단할 때
🔅참고: 기간을 ‘오늘’로 선택한 경우,
누적 추세를 볼 의미가 없기 때문에 이 그래프는 표시되지 않습니다.
누적 그래프는 2일 이상의 기간을 선택했을 때 가장 유용합니다.
💡팁: 누적 그래프는 “이미 얼마나 썼는가”보다 지금 속도가 위험한지 아닌지를 판단하는 데 더 적합한 지표입니다.
latency(지연시간) 분석 · 느려진 이유 찾기
latency는 사용자가 가장 먼저 체감하는 성능 지표입니다.
“왜 갑자기 느려졌는지”는 대부분 아래 네 가지 중 하나로 설명됩니다.
- 모델 : 고성능 모델 사용 비중 증가
- 툴 : Web Search / Reasoning 사용 여부
- 출력 길이 : 출력 토큰이 길어졌는지
- 환경 요인 : 일시적인 네트워크/서버 영향
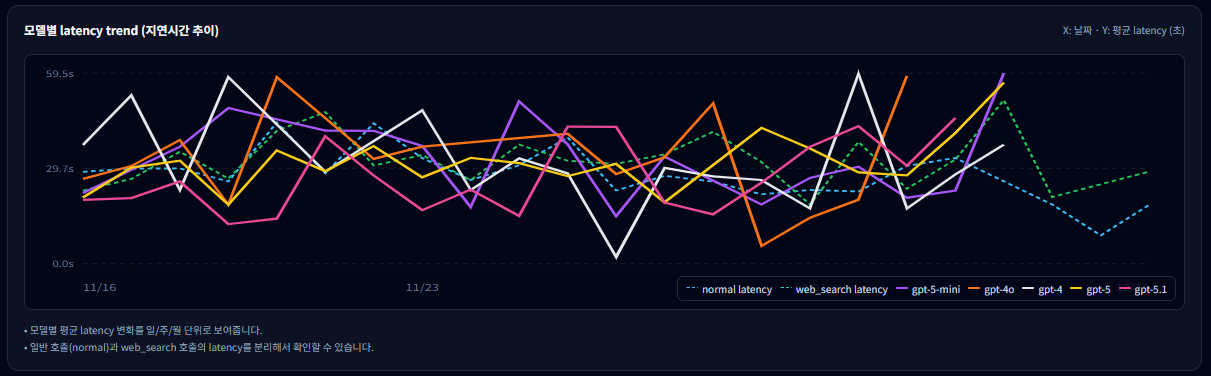
8-1. 모델별 latency trend 읽는 법
- 각 선은 모델별 평균 latency 추이를 의미하며, 일/주/월 버킷 기준으로 변화가 표시됩니다.
- 특정 모델의 선만 유독 위로 튄다면, 해당 모델 사용 비중이 늘었거나 옵션/출력 조건이 달라졌을 가능성이 큽니다.
- 같은 모델에서도 normal latency와 web_search latency가 분리되어 표시되므로, “툴 사용 때문에 느려졌는지”를 명확히 구분할 수 있습니다.
8-2. 비용과 latency를 함께 보는 이유
- latency만 늘고 비용은 그대로라면: 네트워크/일시적 환경 영향 가능성이 큽니다.
- latency와 비용이 함께 늘었다면: Web Search / Reasoning / 장문 출력이 동시에 늘었을 가능성이 높습니다.
- 이 경우 모델별 섹션과 일별 트렌드를 함께 보면 원인을 빠르게 좁힐 수 있습니다.
💡팁: “느려졌다는 느낌”이 들면, 가장 먼저 이 latency 트렌드에서 언제부터 달라졌는지를 확인하고, 그 시점의 모델/툴/호출 리스트로 내려가는 흐름이 가장 빠릅니다.
시간대·요일별 호출 패턴 분석
이 섹션은 “언제 GPT를 가장 많이 쓰고 있는지”를 보여줍니다.
비용 자체보다는 사용 습관과 워크로드 패턴을 파악하는 데 목적이 있습니다.
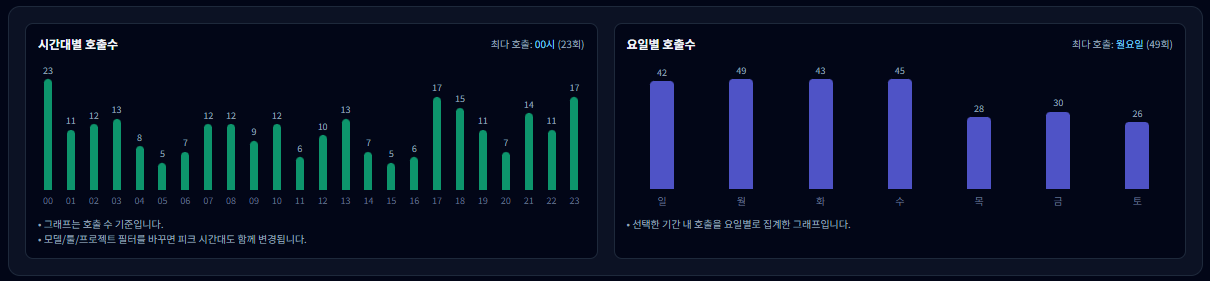
9-1. 시간대별 호출 수(좌측 그래프)
- 하루 24시간을 기준으로 어느 시간대에 호출이 집중되는지를 보여줍니다.
- 업무 시간(예: 9~18시)에 몰려 있다면 업무 자동화/실무 사용 성격이 강합니다.
- 야간·새벽 호출이 많다면 배치 작업, 자동 실행, 개인 실험 가능성을 의심해 볼 수 있습니다.
9-2. 요일별 호출 수(우측 그래프)
- 선택한 기간 동안의 호출을 요일 기준으로 합산해 보여줍니다.
- 평일에 집중된다면 업무/프로젝트 중심 사용, 주말 호출이 많다면 개인 실험·콘텐츠 작업 성향일 수 있습니다.
- 특정 요일만 유난히 높다면, 정기 작업(주간 리포트, 배치 실행)이 있는지 점검해 보세요.
9-3. 이 데이터를 이렇게 활용하세요
- 호출이 특정 시간대에 몰려 있다면: 해당 시간대의 모델/툴 설정을 점검하면 체감 성능 개선에 도움이 됩니다.
- 예상치 못한 시간대(새벽 등)에 호출이 있다면: 자동화 스크립트, 반복 작업이 의도대로 동작하는지 확인합니다.
- 요일별 편차가 크다면: 그 요일의 일별 트렌드·호출 리스트로 내려가 실제 호출 내용을 확인하세요.
💡팁: 이 섹션은 “왜 비쌌는가”보다는
“어떻게 쓰고 있는가”를 점검하는 용도입니다.
비용/latency 분석과 함께 보면, 사용 습관까지 포함한 최적화 포인트가 보이기 시작합니다.
호출 리스트 · 모든 API 호출의 원천 데이터
이 섹션에서는 대시보드에 표시되는 모든 통계의 기반이 되는
개별 API 호출 기록을 그대로 확인할 수 있습니다.
어떤 기능이 언제 호출되었는지, 어떤 모델을 사용했는지,
토큰 사용량과 비용까지 한눈에 확인할 수 있습니다.
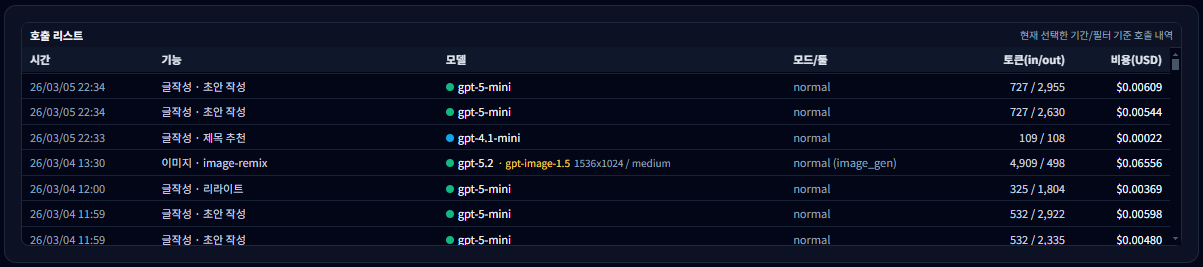
10-1. 호출 리스트에서 확인할 수 있는 정보
- 시간 — API 호출이 발생한 정확한 시점
- 기능 — Playground, Writing, Image Maker 등 어떤 기능에서 호출되었는지
- 모델 — 사용된 OpenAI 모델 (예: gpt-5-mini, gpt-4.1-mini 등)
- 모드/툴 — 일반 실행, 웹검색, 이미지 생성 등 실행 모드
- 토큰(in/out) — 입력 토큰과 출력 토큰 사용량
- 비용 — 해당 호출에 대해 발생한 OpenAI API 비용
10-2. 호출 리스트를 이렇게 활용하세요
- 특정 호출의 비용이 높은 경우, 어떤 기능과 모델이 원인인지 빠르게 확인할 수 있습니다.
- 예상보다 호출 수가 많다면, 자동 반복 실행이나 테스트 루프가 있는지 점검해 볼 수 있습니다.
- Usage 그래프에서 이상 패턴이 발견되면, 해당 시간대의 실제 호출 기록을 직접 확인하는 데 유용합니다.
💡 팁: Usage 대시보드의 그래프는 요약 정보이며,
호출 리스트는 실제 원천 데이터입니다.
비용 분석이나 문제 추적이 필요할 때 가장 먼저 확인해야 하는 영역입니다.
Pro 전용 데이터 관리 · 고급 분석
Pro에서는 실험 규모가 커지고 프로젝트/템플릿 단위 사용이 많아지는 만큼,
분석 범위와 데이터 관리 기능도 한 단계 더 확장됩니다.
이 섹션의 기능들은 모두 Pro 라이선스에서만 제공됩니다.
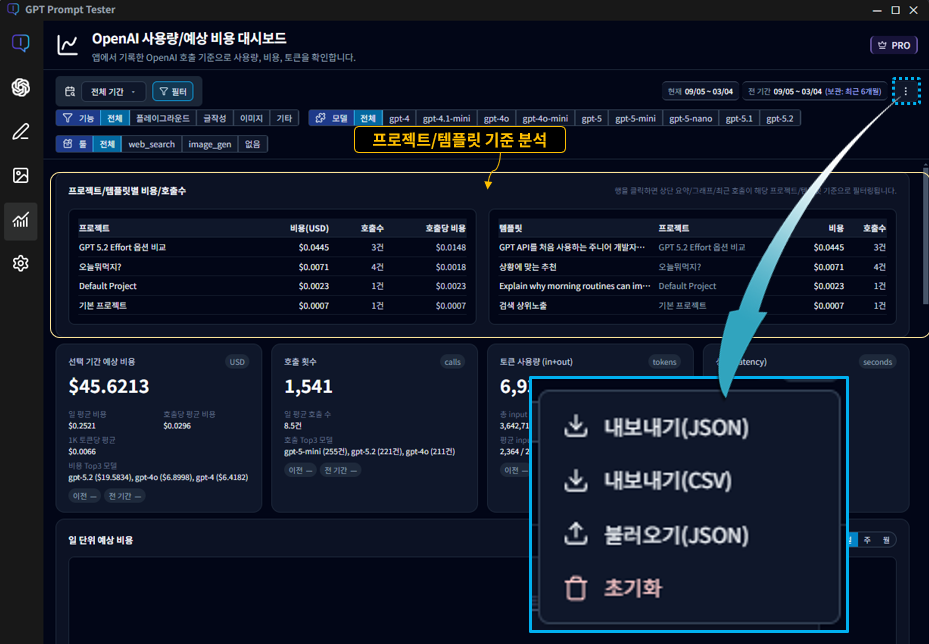
11-1. 프로젝트/템플릿 기반 분석
- 프로젝트/템플릿 필터를 통해 특정 자산이 비용과 호출을 얼마나 사용했는지 분리해서 분석할 수 있습니다.
- 여러 실험을 동시에 진행할수록, “어디에서 비용이 새고 있는지”를 찾는 데 가장 강력한 도구입니다.
- 팀 단위 실험이나 장기 프로젝트에서 비용 책임 범위를 나누는 데 특히 유용합니다.
11-2. 데이터 내보내기 / 불러오기
- 사용량 데이터를 JSON 또는 CSV 파일로 내보내 백업하거나 다른 PC로 이전할 수 있습니다.
- 새 PC 설치, 장비 교체, 장기 분석 보관 시 로컬 데이터를 그대로 유지할 수 있습니다.
- 불러오기(import)를 통해 이전에 저장한 사용량 기록을 다시 복원할 수 있습니다.
⚠️ 주의: 불러오기 시 데이터는 병합 또는 초기화 후 복원 방식으로 처리됩니다. 실행 전 안내 문구를 꼭 확인하세요.
💡Pro는 “기능 추가”라기보다,
실험 규모가 커졌을 때 감당할 수 있게 해주는 확장에 가깝습니다.
Free로 흐름을 익히고, 관리 필요성이 생길 때 Pro로 넘어오는 구성이 가장 자연스럽습니다.
Pro 기능 및 라이선스 비교는 가격 안내 페이지에서 확인하실 수 있습니다.
자주 묻는 질문(비용/쿼터/표시 차이)
Q1. OpenAI 사이트에서 보는 비용과 완전히 일치하나요?
앱은 호출 로그를 기반으로 비용/토큰을 계산하거나 표시합니다.
OpenAI 측 집계와 시간대/집계 방식/반영 시점 차이로
약간의 차이가 있을 수 있습니다.
Q2. 특정 호출이 기록되지 않은 것 같아요.
네트워크 오류나 앱 강제 종료 등으로
일부 호출이 저장되지 않았을 수 있습니다.
재현되는 경우, 발생 시각/모델/상황을 함께 적어
boxkeeper@easymbox.com으로 보내주시면 확인에 도움이 됩니다.
Q3. 비용을 줄이려면 어디부터 보면 좋나요?
보통은 ① 모델별 비용 ② 툴 사용률 ③ 출력 토큰(장문 여부) 순서로 보면 원인을 가장 빨리 찾을 수 있습니다.
다음으로는 아래 문서를 함께 보시면 유지/관리 흐름이 더 좋아집니다.